Yaleで、遊んで学ぶ日々。
Yaleで、遊んで学ぶ日々。
囲碁、ときどきプログラミング、ところにより経済。
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
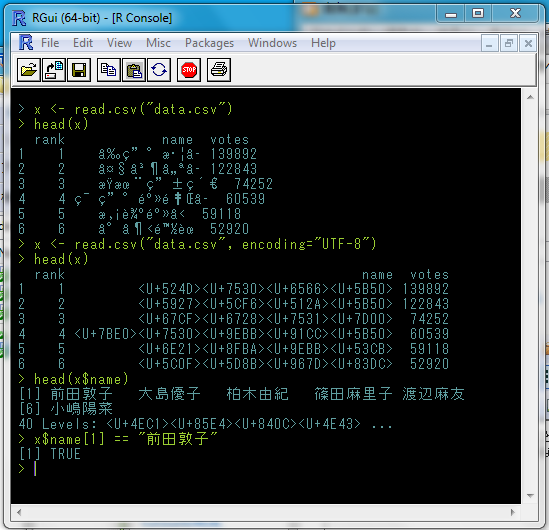
日本で買ったPCなら何の苦もなくできることだが、米国で買ったものだと、そもそも日本語を表示することが念頭にないのか、Rコンソールの文字化けがなかなか治らなかった。3時間かかって何とか表示に成功したのでメモ。
実際に使ったデータは公開できないので以前使ったAKB48のデータで再現。
図のように、普通にデータを読み込んで表示すると日本語部分が文字化けしてしまう。
表示を正しくするには次のようにする。
①ファイルのエンコードはUTF-8にする。
②読み込み時に, encoding="UTF-8" オプションを付ける。
read.csv(filename, encoding="UTF-8")
すると、データフレームの表示がユニコード表示になる。ベクトルで抜き出して表示するときちんと日本語になるし、文字列の比較も上手くいく。
実際に使ったデータは公開できないので以前使ったAKB48のデータで再現。
図のように、普通にデータを読み込んで表示すると日本語部分が文字化けしてしまう。
表示を正しくするには次のようにする。
①ファイルのエンコードはUTF-8にする。
②読み込み時に, encoding="UTF-8" オプションを付ける。
read.csv(filename, encoding="UTF-8")
すると、データフレームの表示がユニコード表示になる。ベクトルで抜き出して表示するときちんと日本語になるし、文字列の比較も上手くいく。
PR
Rでdata.frameを扱っているときに、ある変数の値ごとに何らかの操作をしたい、ということがよくある。例えば、次のような身長と性別のデータがあるとして、「性別ごとに平均を出したい」のようなことだ。
> dat
height gender
1 164.06 0
2 160.83 1
3 162.93 0
4 172.79 1
5 168.85 1
6 162.42 0
7 158.12 1
8 166.14 0
9 174.02 1
10 158.29 1
こういった操作は、by() 関数でできる。
> by(dat, dat$gender, mean)
dat$gender: 0
height gender
163.8875 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
使い方は by(data, INDICES, FUN, ... ) で、
dataには対象となるdata.frame を、 INDICESには場合分けをするための変数を、FUNには使用する関数を与える。FUNの第1引数がdataの部分になり、FUNが他にも引数をとる場合には後に続ける。
例えばデータが欠損値を含んでいる場合、単にmean() で平均を出そうとすると欠損値が返ってくる。欠損値を無視するには、mean() を呼ぶ際に na.rm=T というオプションを加える。
> dat
height gender
1 164.06 0
2 160.83 1
3 NA 0
4 172.79 1
5 168.85 1
6 162.42 0
7 158.12 1
8 166.14 0
9 174.02 1
10 158.29 1
> by(dat, dat$gender, mean)
dat$gender: 0
height gender
NA 0
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
> by(dat, dat$gender, mean, na.rm=T)
dat$gender: 0
height gender
164.2067 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
>
by() 関数の返り値は "by" というクラスなのだが、これはリストを継承する。したがって、インデックスで呼び出すなどの操作も可能。
> b <- by(dat, dat$gender, mean)
> b
dat$gender: 0
height gender
163.8875 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
> names(b)
[1] "0" "1"
> b[[1]]
height gender
163.8875 0.0000
> b[["1"]]
height gender
165.4833 1.0000
> b$`0`
height gender
163.8875 0.0000
上の例では0と1の意味する所が無意味に分かりにくくなってしまっているが、b[[1]] はリストの第1要素(つまりgender:0に対する部分)、b[["1"]] はgender:1に対する部分、b$`0`はgender:0に対する部分を抜き出している。
ちなみに、無理矢理代入することも一応できるようだ。
> b[[1]] <- "replaced"
> b
dat$gender: 0
[1] "replaced"
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
> dat
height gender
1 164.06 0
2 160.83 1
3 162.93 0
4 172.79 1
5 168.85 1
6 162.42 0
7 158.12 1
8 166.14 0
9 174.02 1
10 158.29 1
こういった操作は、by() 関数でできる。
> by(dat, dat$gender, mean)
dat$gender: 0
height gender
163.8875 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
使い方は by(data, INDICES, FUN, ... ) で、
dataには対象となるdata.frame を、 INDICESには場合分けをするための変数を、FUNには使用する関数を与える。FUNの第1引数がdataの部分になり、FUNが他にも引数をとる場合には後に続ける。
例えばデータが欠損値を含んでいる場合、単にmean() で平均を出そうとすると欠損値が返ってくる。欠損値を無視するには、mean() を呼ぶ際に na.rm=T というオプションを加える。
> dat
height gender
1 164.06 0
2 160.83 1
3 NA 0
4 172.79 1
5 168.85 1
6 162.42 0
7 158.12 1
8 166.14 0
9 174.02 1
10 158.29 1
> by(dat, dat$gender, mean)
dat$gender: 0
height gender
NA 0
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
> by(dat, dat$gender, mean, na.rm=T)
dat$gender: 0
height gender
164.2067 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
>
by() 関数の返り値は "by" というクラスなのだが、これはリストを継承する。したがって、インデックスで呼び出すなどの操作も可能。
> b <- by(dat, dat$gender, mean)
> b
dat$gender: 0
height gender
163.8875 0.0000
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
> names(b)
[1] "0" "1"
> b[[1]]
height gender
163.8875 0.0000
> b[["1"]]
height gender
165.4833 1.0000
> b$`0`
height gender
163.8875 0.0000
上の例では0と1の意味する所が無意味に分かりにくくなってしまっているが、b[[1]] はリストの第1要素(つまりgender:0に対する部分)、b[["1"]] はgender:1に対する部分、b$`0`はgender:0に対する部分を抜き出している。
ちなみに、無理矢理代入することも一応できるようだ。
> b[[1]] <- "replaced"
> b
dat$gender: 0
[1] "replaced"
------------------------------------------------------------
dat$gender: 1
height gender
165.4833 1.0000
文字列を大文字・小文字に変換するには、toupper(), tolower() 関数を使う。
> toupper("United States of America")
[1] "UNITED STATES OF AMERICA"
> tolower("I live in Tokyo, Japan")
[1] "i live in tokyo, japan"
> toupper("United States of America")
[1] "UNITED STATES OF AMERICA"
> tolower("I live in Tokyo, Japan")
[1] "i live in tokyo, japan"
あるベクトルの累積和(第 j 要素がもとのベクトルの1~j 番までの和となるような同サイズのベクトル)を作りたいときは、cumsum() 関数を使う。
>cumsum(c(0,1,0,1,1,0))
[1] 0 1 1 2 3 3
> cumsum(c(0.1, 0.4, 0.2, 0.05, 0.15, 0.1))
[1] 0.10 0.50 0.70 0.75 0.90 1.00
>cumsum(c(0,1,0,1,1,0))
[1] 0 1 1 2 3 3
> cumsum(c(0.1, 0.4, 0.2, 0.05, 0.15, 0.1))
[1] 0.10 0.50 0.70 0.75 0.90 1.00
Rによるディレクトリ・ファイル操作メモ
dir.create(): ディレクトリ作成。オプション recursive=TRUE を設定すれば階層のあるディレクトリ構造を作ることも可。
* pythonでいう os.mkdir(), os.makedirs()
file.exists(): ファイルやディレクトリの存在を確認。
* pythonでいう os.path.exists()
file.path(): パスの結合。
* pythonでいう os.path.join()
dir.create(): ディレクトリ作成。オプション recursive=TRUE を設定すれば階層のあるディレクトリ構造を作ることも可。
* pythonでいう os.mkdir(), os.makedirs()
file.exists(): ファイルやディレクトリの存在を確認。
* pythonでいう os.path.exists()
file.path(): パスの結合。
* pythonでいう os.path.join()
Calender
| 06 | 2026/07 | 08 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Search in This Blog
Latest Comments
[03/30 川内のばば山田]
[03/30 川内のばば山田]
[08/06 Aterarie]
[07/05 Agazoger]
[07/01 Thomaskina]
Latest Posts
(11/16)
(04/28)
(04/16)
(04/11)
(04/05)
Latest Trackbacks
Category
フリーエリア

Barcode
Access Analysis