Yaleで、遊んで学ぶ日々。
Yaleで、遊んで学ぶ日々。
囲碁、ときどきプログラミング、ところにより経済。
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
KGS対局(3子局の白)。ここ最近で何番目かに酷い碁。
大間違いで中央を切り離された。白1は苦し紛れのコウ狙い。黒2に受けてくれたので白3でかろうじて生き。しかし投げても良いくらい。
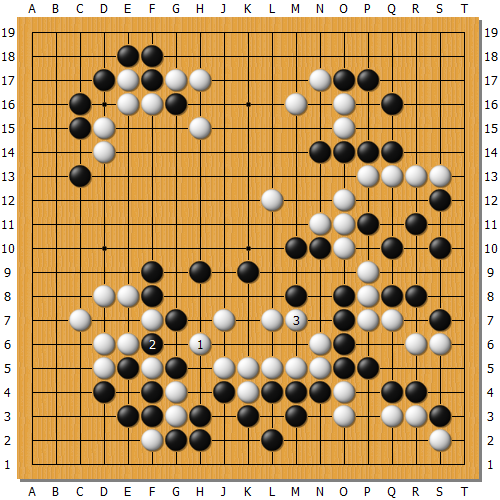
しばらく進んで、右上の黒を狙う。黒△で全滅は免れていて、AとBが見合い。
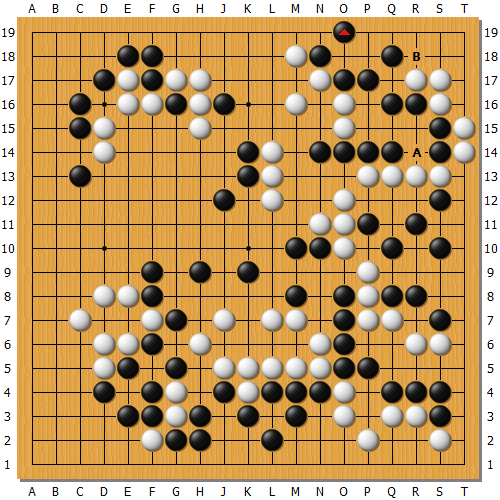
仕方がないので2目を取って手を打つ。白5は自分のダメを詰めて意味不明。黒8に受けてくれたので、左下に回れて少しホッとする。
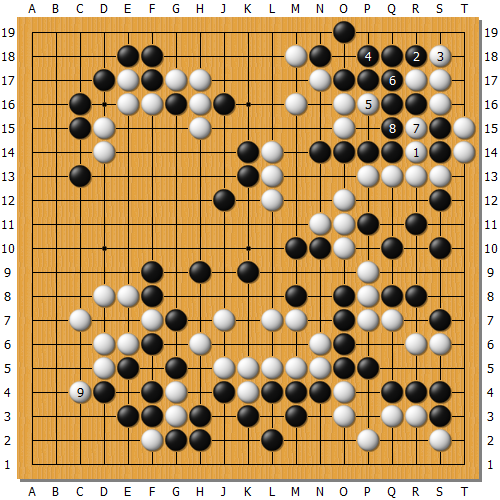
さらに進んで、黒1から上辺を取りに来た。反撃のチャンス。

白6から渡りを利かしてから16の切りで上辺は助かった。手順中、黒11の放り込みが悲劇。調子で白12に石が来て、右上黒が頓死して逆転勝ち。黒11で単に13なら右上はコウ。黒19で20と右上を生きるなら、白19で細かいヨセ勝負になっていたらしい。また、黒13のときに白20と右上と攻め合うと、白が取り番のコウ。

大間違いで中央を切り離された。白1は苦し紛れのコウ狙い。黒2に受けてくれたので白3でかろうじて生き。しかし投げても良いくらい。
しばらく進んで、右上の黒を狙う。黒△で全滅は免れていて、AとBが見合い。
仕方がないので2目を取って手を打つ。白5は自分のダメを詰めて意味不明。黒8に受けてくれたので、左下に回れて少しホッとする。
さらに進んで、黒1から上辺を取りに来た。反撃のチャンス。
白6から渡りを利かしてから16の切りで上辺は助かった。手順中、黒11の放り込みが悲劇。調子で白12に石が来て、右上黒が頓死して逆転勝ち。黒11で単に13なら右上はコウ。黒19で20と右上を生きるなら、白19で細かいヨセ勝負になっていたらしい。また、黒13のときに白20と右上と攻め合うと、白が取り番のコウ。
最後に中央白の死活。黒1の割り込みに外から抑えるのが大切。白生き。

黒1から来ても白2から二眼ある。

黒1から来ても白2から二眼ある。
PR
import os
import time
import urlparse
import datetime
import csv
import urllib2
import urllib
import BeautifulSoup
import re
# 0 ベクトル, リストの繰り返し #
[0] * 10
['a', 'b', 'c'] * 3
# ディレクトリの中身一覧 #
os.listdir("Desktop")
# パスから拡張子を分割(返り値は長さ2のリスト)#
os.path.splitext("Desktop/folder/subfolder/file.txt")
# パスからファイル名だけを抜き出し #
os.path.basename("Desktop/folder/subfolder/file.txt")
# パスの結合 #
os.path.join("Desktop", "folder/file.pdf")
# URLの結合 #
urlparse.urljoin("http://jiy.blog.shinobi.jp/", "Entry/274/")
# しばらく止める(単位は秒)#
time.sleep(5)
# 文字列の頭とお尻のスペースを消す #
' abc def g '.strip()
' abc def g '.lstrip()
' abc def g '.rstrip()
# 現在の時間 #
# そのまま文字列として使おうとするとエラーが起こることがあるので、strtime関数で文字列にする。
import datetime
tm = datetime.datetime.today()
tm
tm.strftime('%Y-%m-%d_%H-%M-%S')
# リスト内で、特定の値に等しい要素番号の最小値 #
['A', 'B', 'B', 'C'].index('B')
# 辞書(dictionary)のkeyの一覧 #
d = { "name":"tarou" , "address":"tokyo", "age":30, "hobby":["igo", "chess", "shogi"] }
d.keys()
# 集合演算 #
# list() でリストに変換できる。
set(range(5)) & set(range(3))
set(['a', 'b']) | set(['a', 'c', 'd'])
set(range(4)) - set([2])
# リスト内の重複を取り除く #
# 一度集合にしてからリストにすれば良い。ただし順番は狂う。
x = ['a', 'b', 'c', 'b', 'c']
list(set(x))
# リストをCSVに保存 #
x = [ ["x", "y", "z"], [10, 5, 3], [1, "XYZ", 3], ["5", 1, "ABC"] ]
with open("test.csv", 'wb') as f:
ff = csv.writer(f)
for row in x:
ff.writerow(row)
# 辞書をCSVに保存 #
# データは辞書のリスト
data = [ {"name":"ichiro", "age":20} , {"name":"tarou", "age":15} ,{"name":"takuro", "age":30} ]
head = ("name", "age")
with open("test.csv", 'wb') as f:
ff = csv.DictWriter(f, head)
for row in data:
ff.writerow(row)
# ヘッダー行を入れるためのテクニック
data = [ {"name":"ichiro", "age":20} , {"name":"tarou", "age":15} ,{"name":"takuro", "age":30} ]
head = ("name", "age")
with open("test.csv", 'wb') as f:
ff = csv.DictWriter(f, head)
# ここ
row = dict( (n, n) for n in head )
for row in data:
ff.writerow(row)
# web pageのソースを取得 #
urllib2.urlopen("http://jiy.blog.shinobi.jp/Entry/274/").read()
# ファイルをダウンロード
urllib.urlretrieve(""http://bfile.shinobi.jp/admin/img/blogheader_logo.png"", "file.png")
# HTML ソースの処理(web scraping) #
src = urllib2.urlopen("http://jiy.blog.shinobi.jp/").read()
soup = BeautifulSoup.BeautifulSoup(src)
# タグとそのオプションを指定して検索
divs = soup("div", {"class":"EntryTitle"})
divs[0]
# タグを除去
ttl = str(divs[2])
re.sub("<[^<>]*>", "", ttl)
# タグのオプションの値を検索
imgs = soup("img")
imgs[2].get("src")
import time
import urlparse
import datetime
import csv
import urllib2
import urllib
import BeautifulSoup
import re
# 0 ベクトル, リストの繰り返し #
[0] * 10
['a', 'b', 'c'] * 3
# ディレクトリの中身一覧 #
os.listdir("Desktop")
# パスから拡張子を分割(返り値は長さ2のリスト)#
os.path.splitext("Desktop/folder/subfolder/file.txt")
# パスからファイル名だけを抜き出し #
os.path.basename("Desktop/folder/subfolder/file.txt")
# パスの結合 #
os.path.join("Desktop", "folder/file.pdf")
# URLの結合 #
urlparse.urljoin("http://jiy.blog.shinobi.jp/", "Entry/274/")
# しばらく止める(単位は秒)#
time.sleep(5)
# 文字列の頭とお尻のスペースを消す #
' abc def g '.strip()
' abc def g '.lstrip()
' abc def g '.rstrip()
# 現在の時間 #
# そのまま文字列として使おうとするとエラーが起こることがあるので、strtime関数で文字列にする。
import datetime
tm = datetime.datetime.today()
tm
tm.strftime('%Y-%m-%d_%H-%M-%S')
# リスト内で、特定の値に等しい要素番号の最小値 #
['A', 'B', 'B', 'C'].index('B')
# 辞書(dictionary)のkeyの一覧 #
d = { "name":"tarou" , "address":"tokyo", "age":30, "hobby":["igo", "chess", "shogi"] }
d.keys()
# 集合演算 #
# list() でリストに変換できる。
set(range(5)) & set(range(3))
set(['a', 'b']) | set(['a', 'c', 'd'])
set(range(4)) - set([2])
# リスト内の重複を取り除く #
# 一度集合にしてからリストにすれば良い。ただし順番は狂う。
x = ['a', 'b', 'c', 'b', 'c']
list(set(x))
# リストをCSVに保存 #
x = [ ["x", "y", "z"], [10, 5, 3], [1, "XYZ", 3], ["5", 1, "ABC"] ]
with open("test.csv", 'wb') as f:
ff = csv.writer(f)
for row in x:
ff.writerow(row)
# 辞書をCSVに保存 #
# データは辞書のリスト
data = [ {"name":"ichiro", "age":20} , {"name":"tarou", "age":15} ,{"name":"takuro", "age":30} ]
head = ("name", "age")
with open("test.csv", 'wb') as f:
ff = csv.DictWriter(f, head)
for row in data:
ff.writerow(row)
# ヘッダー行を入れるためのテクニック
data = [ {"name":"ichiro", "age":20} , {"name":"tarou", "age":15} ,{"name":"takuro", "age":30} ]
head = ("name", "age")
with open("test.csv", 'wb') as f:
ff = csv.DictWriter(f, head)
# ここ
row = dict( (n, n) for n in head )
ff.writerow(row)
ff.writerow(row)
# web pageのソースを取得 #
urllib2.urlopen("http://jiy.blog.shinobi.jp/Entry/274/").read()
# ファイルをダウンロード
urllib.urlretrieve(""http://bfile.shinobi.jp/admin/img/blogheader_logo.png"", "file.png")
# HTML ソースの処理(web scraping) #
src = urllib2.urlopen("http://jiy.blog.shinobi.jp/").read()
soup = BeautifulSoup.BeautifulSoup(src)
# タグとそのオプションを指定して検索
divs = soup("div", {"class":"EntryTitle"})
divs[0]
# タグを除去
ttl = str(divs[2])
re.sub("<[^<>]*>", "", ttl)
# タグのオプションの値を検索
imgs = soup("img")
imgs[2].get("src")
Calender
| 04 | 2026/05 | 06 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Search in This Blog
Latest Comments
[03/30 川内のばば山田]
[03/30 川内のばば山田]
[08/06 Aterarie]
[07/05 Agazoger]
[07/01 Thomaskina]
Latest Posts
(11/16)
(04/28)
(04/16)
(04/11)
(04/05)
Latest Trackbacks
Category
フリーエリア

Barcode
Access Analysis