Yaleで、遊んで学ぶ日々。
Yaleで、遊んで学ぶ日々。
囲碁、ときどきプログラミング、ところにより経済。
×
[PR]上記の広告は3ヶ月以上新規記事投稿のないブログに表示されています。新しい記事を書く事で広告が消えます。
PythonにおけるHTML scrapingにはBeautifulSoupが欠かせないが、その全貌がよくわかってなかった。どうも正規表現を簡潔に記述する機能としか理解していなかったのだが、実際は、HTMLソースをツリー階層に処理して、直感的に解析するツールになっている。特定のタグを検索するくらいだと気にならないが、要素間移動を利用したところ(事実ある種の作業にはこれが不可欠になる)、その一端に触れることができた。
テストコード。まだ完全には理解できていない。
テストコード。まだ完全には理解できていない。
from bs4 import BeautifulSoup
html = """
<body>
<a>A tag</a>
whatever outside <br> <br/>
<a>iyay <i> somthing inside </i> </a>
</body>
"""
soup = BeautifulSoup(html)
print 'navigation by "find_next()" method'
a = soup.a
for i in range(10):
if i == 1:
print type(a)
print i, ':', a
a = a.find_next()
if not a:
break
print '\n'
print 'navigation by "find_next_sibling()" attribute'
a = soup.a
for i in range(10):
if i == 1:
print type(a)
print i, ':', a
a = a.find_next_sibling()
if not a:
break
print '\n'
print 'navigation by "next_sibling" attribute'
a = soup.a
for i in range(10):
if i == 1:
print type(a)
print i, ':', a
a = a.next_sibling
if not a:
break
print '\n'
print 'navigation by "next_element" attribute'
a = soup.a
for i in range(10):
if i == 1:
print type(a)
print i, ':', a
a = a.next_element
if not a:
break
出力結果:
navigation by "find_next()" method
0 : <a>A tag</a>
<class 'bs4.element.Tag'>
1 : <br/>
2 : <br/>
3 : <a>iyay <i> somthing inside </i> </a>
4 : <i> somthing inside </i>
navigation by "find_next_sibling()" attribute
0 : <a>A tag</a>
<class 'bs4.element.Tag'>
1 : <br/>
2 : <br/>
3 : <a>iyay <i> somthing inside </i> </a>
navigation by "next_sibling" attribute
0 : <a>A tag</a>
<class 'bs4.element.NavigableString'>
1 :
whatever outside
2 : <br/>
3 :
4 : <br/>
5 :
6 : <a>iyay <i> somthing inside </i> </a>
7 :
navigation by "next_element" attribute
0 : <a>A tag</a>
<class 'bs4.element.NavigableString'>
1 : A tag
2 :
whatever outside
3 : <br/>
4 :
5 : <br/>
6 :
7 : <a>iyay <i> somthing inside </i> </a>
8 : iyay
9 : <i> somthing inside </i>
PR
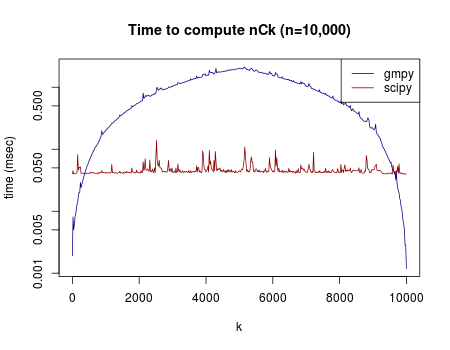
組み合わせ(n C k )を計算する時間は、nが大きくなるにつれて大きくなる。一番時間がかかるのはkがちょうどnの半分のところ(階乗の計算が大変)。逆にk=1またはk=nの時は、n C k = 1 なので簡単。
pythonでn C k を計算する関数としては、gmpy.comb() とscipy.misc.comb() の2つが有名どころらしい(参考URL)。このうち、gmpy.comb()は正確に組み合わせの数を計算するのに対して、scipy.misc.comb()のほうは、対数ガンマ関数を利用して近似値を返すらしい。そのため、後者のほうがスピードが速いとか。
実験してみたところ、次のような結果になった。
n = 10000を固定して、k の値を1から10000まで、色々変えて、それぞれの関数でn C k の計算にかかる時間を記録した。グラフのy軸は経過時間(ミリ秒)で。対数にしてある。
予想通り、gmpyのほうは階乗の計算が難しくなる中間のkについて、計算時間は長くなり、真ん中(k=5000)のあたりで最大になる。一方、近似値を計算するscipyの方は、そういった問題が起こらないらしく、一定の速度で計算できるらしい。そもそも計算の簡単な範囲(kが1に近いかnに近いか)では、gmpyで計算したほうが速いということもグラフから分かる。
使用したファイル:comb_test.py, comb-graph.R
pythonでn C k を計算する関数としては、gmpy.comb() とscipy.misc.comb() の2つが有名どころらしい(参考URL)。このうち、gmpy.comb()は正確に組み合わせの数を計算するのに対して、scipy.misc.comb()のほうは、対数ガンマ関数を利用して近似値を返すらしい。そのため、後者のほうがスピードが速いとか。
実験してみたところ、次のような結果になった。
n = 10000を固定して、k の値を1から10000まで、色々変えて、それぞれの関数でn C k の計算にかかる時間を記録した。グラフのy軸は経過時間(ミリ秒)で。対数にしてある。
予想通り、gmpyのほうは階乗の計算が難しくなる中間のkについて、計算時間は長くなり、真ん中(k=5000)のあたりで最大になる。一方、近似値を計算するscipyの方は、そういった問題が起こらないらしく、一定の速度で計算できるらしい。そもそも計算の簡単な範囲(kが1に近いかnに近いか)では、gmpyで計算したほうが速いということもグラフから分かる。
使用したファイル:comb_test.py, comb-graph.R
データ整理から集計、行列演算、統計分析まで、全部pythonで済ませられないか・・・? データを扱う場合に、それがリストのリストとして定義されているのだと、縦の操作に弱い。例えば、列を対象にした操作ができない。統計ソフトであれば簡単にできる、第1列と第2列を足す、というような単純な操作にforループを回すのではいただけない。Rでいうところのdata.frameにあたるようなオブジェクトはないものかと探したところ、pandasというデータ解析ツールが最近開発されていることを知った。Ubuntu12.04以降は公式レポジトリに入っている。そうでない場合は、公式ページから自分で構築することになる。
pandasは、一言で言えばRのファンがpythonに移植した、という印象で、Rからの漂流者には比較的優しい仕様になっている。一番の売りは、DataFrameというそのものずばりのクラスが定義されていることで、これを科学計算パッケージであるnumpy, scipyと組み合わせることで統計ソフトの仕事を全部こなしてやろう、というプロジェクトと見える。
pandasについては目下のところ勉強中だが、今のところ印象はかなり良い。Rの良い機能を再現しながら、pythonならではの整合性を保っているという印象。計量経済学などはどこまで出来るのかまだわからないが、詰まるところは行列演算と最適化なわけだから、自分で書くこともできるし、そのうち誰かが(あるいはすでに)実装するだろう。実現可能なことはいずれ必ず起こるのだ。
統計ソフトの役割を果たそうとすると、必ずインタラクティブな操作が必要になる。データを読み込んだら、とりあえず集計したり、上の5行くらいを眺めたり、バグがないかチェックしたり、ということをしたい。端末から毎度回すのでは不便すぎるので、必然的にインタープリタを使うことになる。インタープリタ上で、スクリプトファイルを回すには
execfile("filepath.py")
を使う。
では、スクリプトの一部を回すにはどうすればいいか? 専用エディタがあれば普通にある機能だけど・・・。とりあえず、コピペで対処するくらいかな。
pandasは、一言で言えばRのファンがpythonに移植した、という印象で、Rからの漂流者には比較的優しい仕様になっている。一番の売りは、DataFrameというそのものずばりのクラスが定義されていることで、これを科学計算パッケージであるnumpy, scipyと組み合わせることで統計ソフトの仕事を全部こなしてやろう、というプロジェクトと見える。
pandasについては目下のところ勉強中だが、今のところ印象はかなり良い。Rの良い機能を再現しながら、pythonならではの整合性を保っているという印象。計量経済学などはどこまで出来るのかまだわからないが、詰まるところは行列演算と最適化なわけだから、自分で書くこともできるし、そのうち誰かが(あるいはすでに)実装するだろう。実現可能なことはいずれ必ず起こるのだ。
統計ソフトの役割を果たそうとすると、必ずインタラクティブな操作が必要になる。データを読み込んだら、とりあえず集計したり、上の5行くらいを眺めたり、バグがないかチェックしたり、ということをしたい。端末から毎度回すのでは不便すぎるので、必然的にインタープリタを使うことになる。インタープリタ上で、スクリプトファイルを回すには
execfile("filepath.py")
を使う。
では、スクリプトの一部を回すにはどうすればいいか? 専用エディタがあれば普通にある機能だけど・・・。とりあえず、コピペで対処するくらいかな。
Pythonを使い始めてしばらく経つが、初めて参照と値の違いによるバグが生じた。次のA-Cの結果はそれぞれどうなるだろうか。
# (A)
答えは、
(A): ['a0', 'a1', 'a2', 'a3', 'a4']
(B): [['a0'], ['a1'], ['a2'], ['a3'], ['a4']]
(C) については、xの各要素がすべて同じsを参照しているため、sの値を変えるたびにそれがxに反映されてしまう。
一方(B)では、forループ内で毎回sを定義しなおしているので、xの各要素はそれぞれ異なるモノを参照している。
他にも色々試してみる。
次のコードの場合、xへの変更はyに反映されない。
この場合も、反映されない。
ということは、y = x という形の場合は参照になるが、y = x[j] という形の場合は値の代入になるのかな。あるいは、x[j]と書いた瞬間にその要素の複製を作っているので、これはx本体とは区別されるということだろうか。
# (A)
x = []
s = ""
for i in range(5):
s = "a" + str(i)
x.append(s)
print x
# (C)
# (B)
x = []
s = [""]
for i in range(5):
s = [ "a" + str(i) ]
x.append(s)
print x
x = []
s = [""]
for i in range(5):
s[0] = "a" + str(i)
x.append(s)
print x
答えは、
(A): ['a0', 'a1', 'a2', 'a3', 'a4']
(B): [['a0'], ['a1'], ['a2'], ['a3'], ['a4']]
(C): [['a4'], ['a4'], ['a4'], ['a4'], ['a4']]
一方(B)では、forループ内で毎回sを定義しなおしているので、xの各要素はそれぞれ異なるモノを参照している。
他にも色々試してみる。
次のコードの場合、xへの変更はyに反映されない。
x = [["a"], ["b"], ["c"]]
y = [[""], [""] , [""]]
for i in range(3):
y[i] = x[i]
print "x", x, "y", y
x[0] = ["d"]
print "x", x, "y", y
この場合も、反映されない。
x = [["a"], ["b"], ["c"]]
y = x[0]
print "x", x, "y", y
x[0] = ["d"]
print "x", x, "y", y
ということは、y = x という形の場合は参照になるが、y = x[j] という形の場合は値の代入になるのかな。あるいは、x[j]と書いた瞬間にその要素の複製を作っているので、これはx本体とは区別されるということだろうか。
Calender
| 06 | 2026/07 | 08 |
| S | M | T | W | T | F | S |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Search in This Blog
Latest Comments
[03/30 川内のばば山田]
[03/30 川内のばば山田]
[08/06 Aterarie]
[07/05 Agazoger]
[07/01 Thomaskina]
Latest Posts
(11/16)
(04/28)
(04/16)
(04/11)
(04/05)
Latest Trackbacks
Category
フリーエリア

Barcode
Access Analysis